Responsible AI

Which levers do we pull?
In 2023, CSIRO published Responsible AI: Best Practices for Creating Trustworthy AI Systems.
The book is a compilation of guidelines to assist in implementing governance, process and product considerations into AI systems:

"Responsible AI is the practice of developing and using AI systems in a way that provides benefits to individuals, groups, and wider society, while minimizing the risk of negative consequences." (Xu, Whittle, Zhu, & Lu, 2023, p. 18).
How can we make use of this fantastic resource to support development teams, consultants and governing bodies? I'm going to attempt to improve on efforts to operationalise research by the team at CSIRO Data61.[[2]]
Improving the usability of RAI patterns
We start with the notion that product, process and governance practices are causally interrelated and complex.
This departs from most conceptualisations of RAI patterns as containment hierarchies or trees:
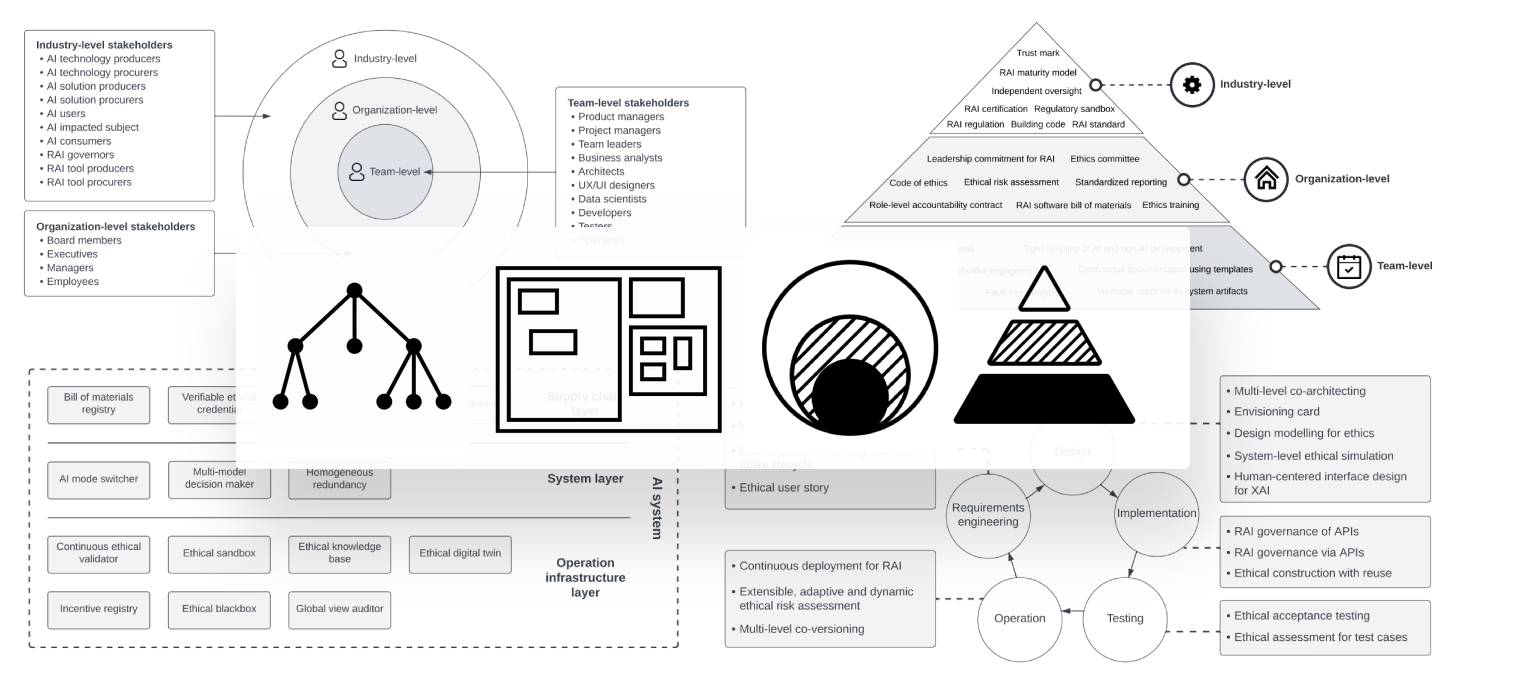
The hierarchies above cannot adequately express complexity—instead we can model RAI practices as a directed graph of causal connections:
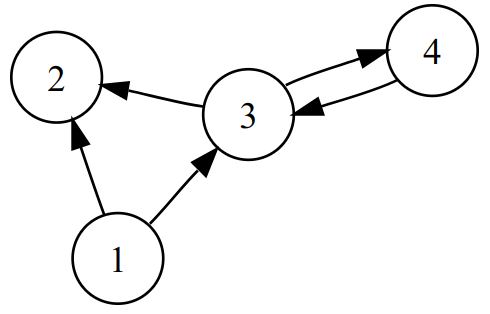
Why use a graph instead of organising content by theme?
- Actions toward RAI can be interpreted based on their cause and effect
- RAI patterns can be re-organised to support actions with the maximum impact.
By finding reinforcing feedback loops in our graph, we can prioritise actions that accelerate accountability, transparency, reliability and safety—or alternatively, balancing loops can limit or goal-seek to mitigate risk or harm, etc.
Inferring the causal structure of RAI
Thankfully the written compilation of patterns is already well structured[[3]], so with some data wrangling, it can be converted into a dataframe:
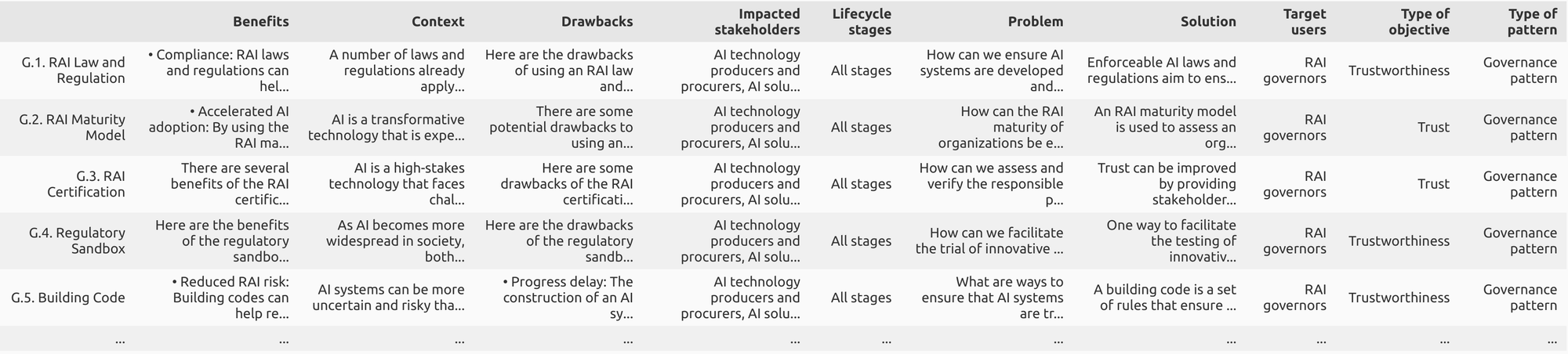
How can we convert this into a graph?
We can use a Large Language Model (LLM) and some procedural prompt engineering to follow constraints and conditions. Some common techniques were used to create an effective prompt:
- Chain-of-thought (COT) [[4]]
- EmotionPrompt [[5]]
- Expert prompting [[6]]
- Generated knowledge [[7]]
- Least to most [[8]]
Below is a snippet of the main function only — making use of the fantastic️ Python package LMQL and chat-gpt 3.5 turbo instruct for the LLM model.

Unsurprisingly the results are typical of all LLMs to date; impressive and imperfect. But this provides a useful starting point for the work of skilled modelers.
The graph below is generated from the chapter G.4. Regulatory Sandbox (Xu, Whittle, Zhu, & Lu, 2023, p. 65). In the graph, both balancing and reinforcing loops are present and although most loops seem plausible, the intermediate causal factors between nodes can be absent.
Regulatory Sandbox
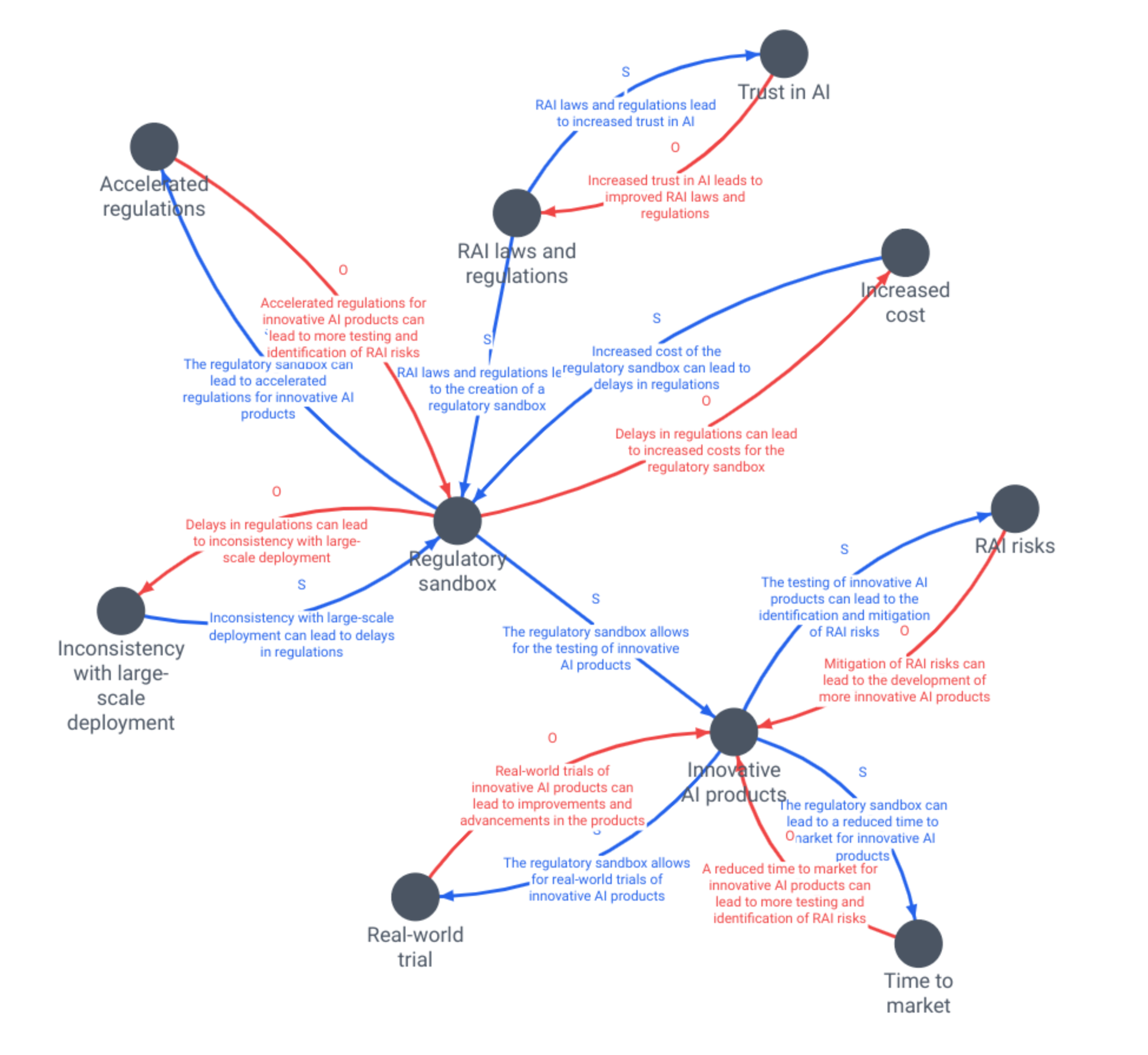

Looking for leverage
Let's discover the feedback loops that may reveal actions or events that are mutually reinforcing, or balancing with “goal-seeking” behaviour.
Remember, these causal factors (dots) are present across different patterns, and so merging them uncovers even more feedback loops!
First a lovely hairball appears when aggregating all RAI factors
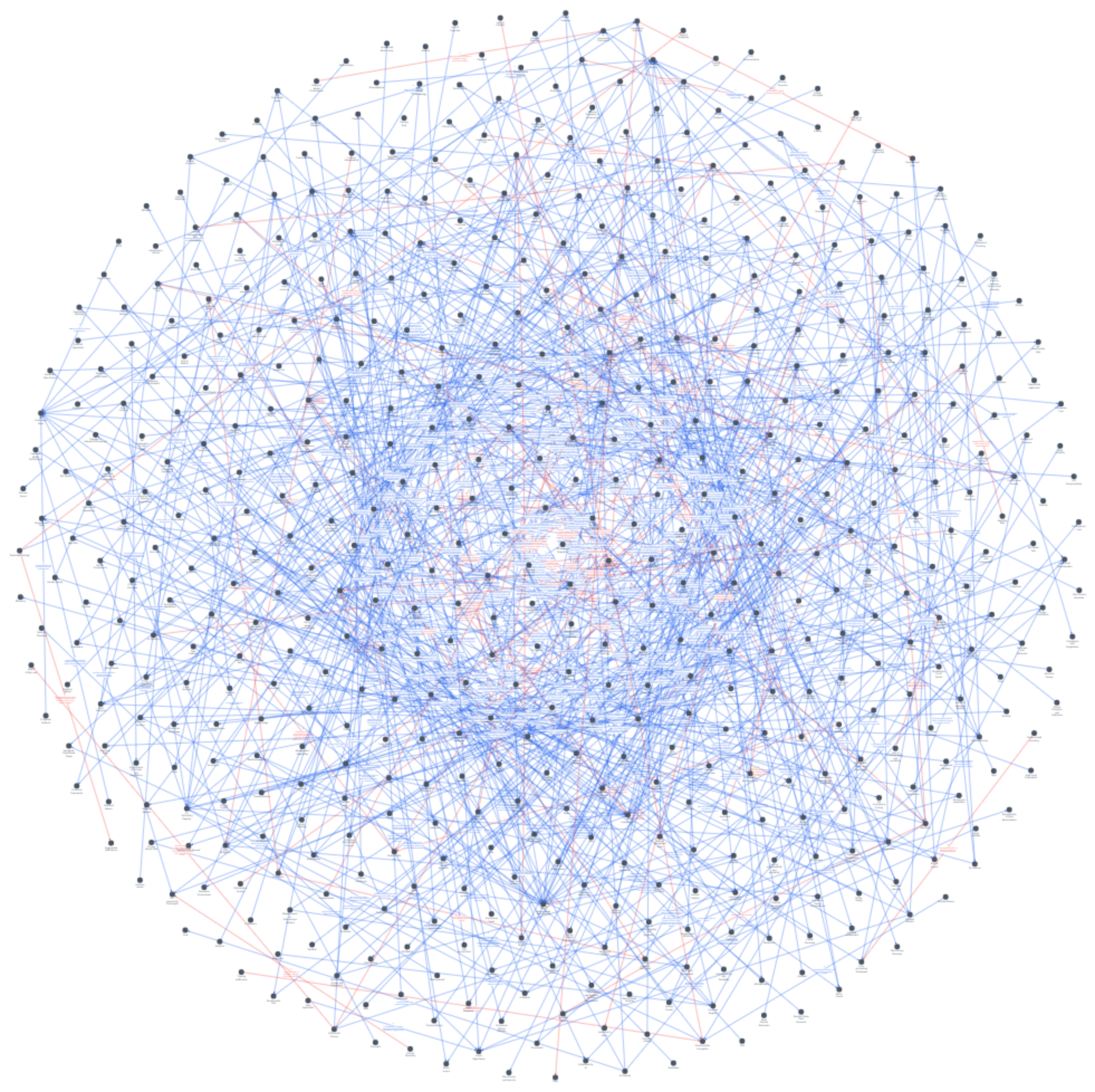
To reduce the number of nodes, we can merge them based on duplicates or similar meaning. In the scatter plot below, I used word vector embeddings to show causal factors across RAI patterns (dots) clustered by similar meaning/context. I use the PaCMAP dimensional reduction and cosine similarity with sentence-transformers/all-mpnet-base-v2 embeddings model.
Hover to see the corresponding text:
The next step is to find the feedback loops. We can use a graph algorithm to find them for us using networkx; the simple_cycles function:

If we merge based on these clusters and duplicate names, we can use graph algorithm reinforcing or balancing feedback loops.
Orange = Balancing loops Blue = reinforcing loops
42 loops were found
Let's examine some of the loops to see if they consist of actions or events that accelerate measures of accountability, transparency, reliability, safety– or limit risk, harm, etc.
The first one has 9 factors causally linked, where every factor increases or adds to the next one. This is a "B" balancing loop.
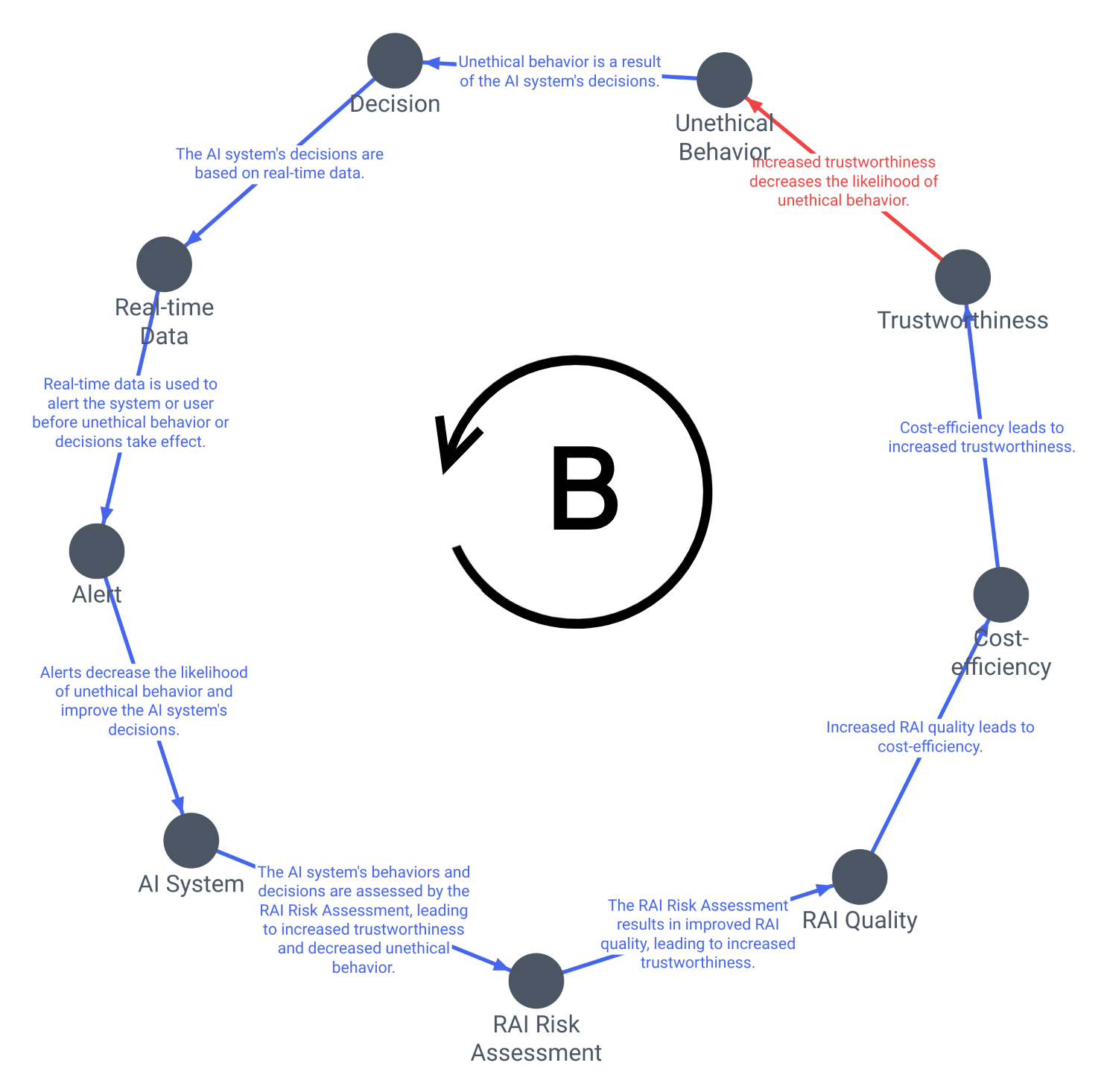
Let's observe a few important points about this graph
- It's a loop because the path starts and finishes at the same factor; each one is causally linked to the next; a "directed cycle" in graph theory.
- It's balancing because the count of red/blue polarities (a subjective judgement about its effect) is odd — Eg: an odd number of U-turns keeps you headed in the opposite direction.[[9]]
- Balancing loops are "goal seeking" because they counteract deviations from a target state. Increasing any of these factors will continue to drive the system towards that state.
There are however are few problems with this loop:
- Not all factors are described as sensible quantities. Better prompts may significantly improve LLM output and the resulting causal graph.
- What is driving the loop? it helps to view factors outside the loop:
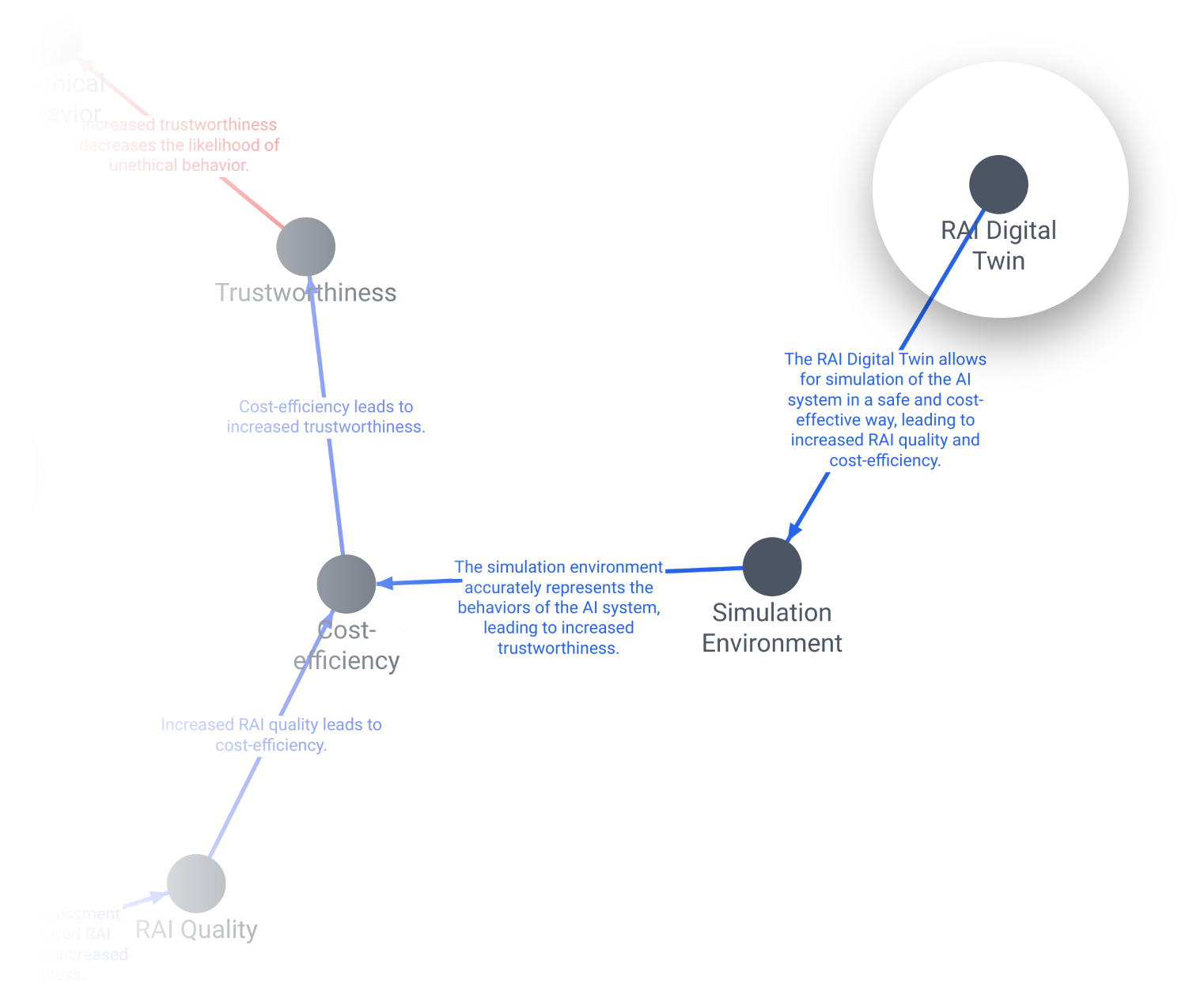
It would be exciting to uncover feedback loops that consist of factors from multiple RAI patterns. In the loop above, the factors that comprise it are described in a single RAI pattern; the "D.11. Digital Twin". Despite links between those factors and others outside of the Digital Twin pattern, none of them combined to form this particular loop. Finding these "hybrid factor" loops is an interesting direction for further research.
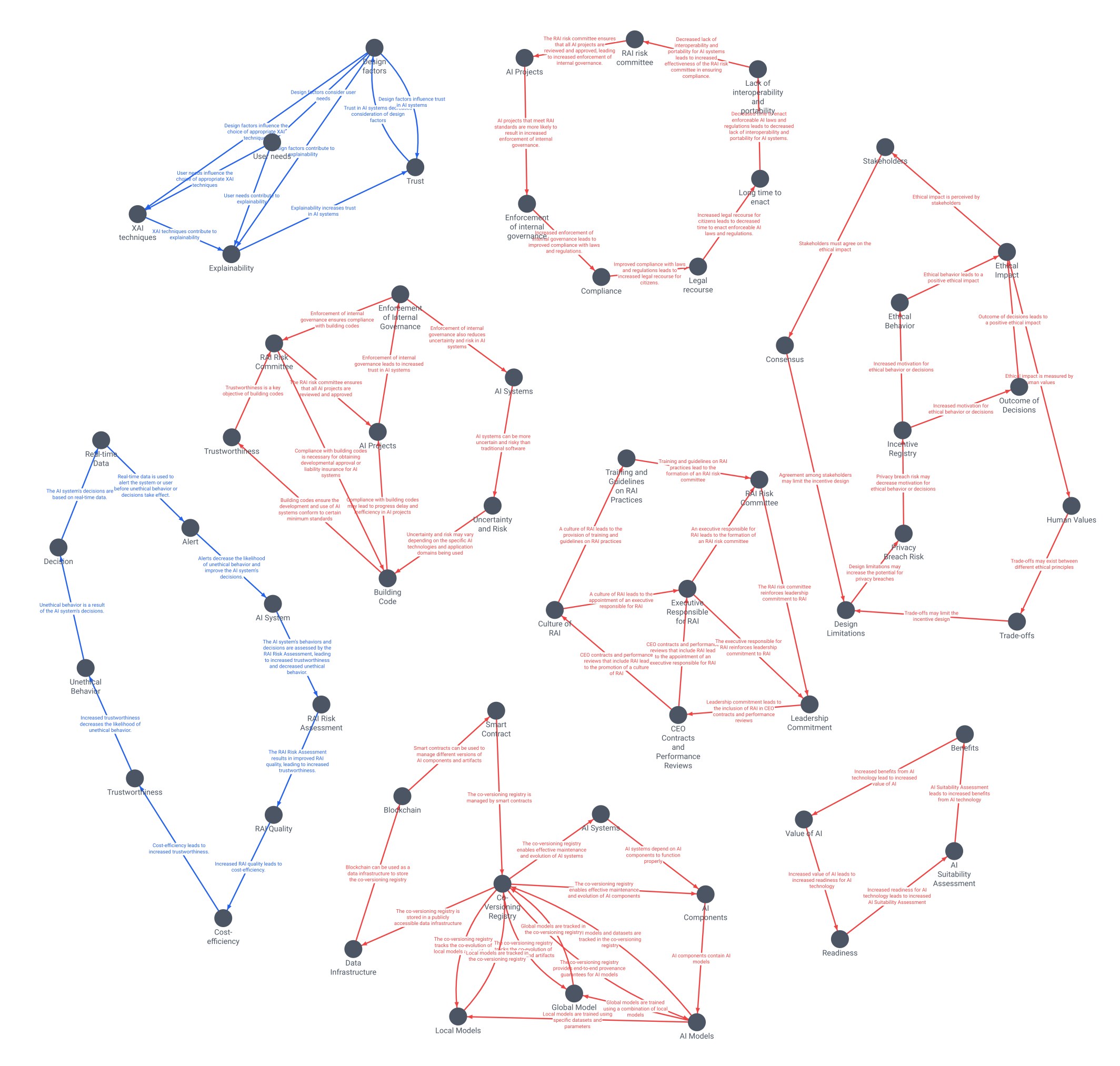
How reliable are these causal graphs?
The quality, coherence and external validity of the RAI patterns published by CSIRO Data61 provides a solid foundation for causal analysis, and I believe it is safe to assume there are causal relationships among them.
Systems modelling is an established field of research, and "causal loop diagramming" on which my approach is based has been used extensively in various industries; climate policy simulation and COVID-19 policy are recent examples.
The reliability of AI-assisted and computational causal modelling presented here hinges on the validity of the computational approach. I believe this remains in the hands of the experience of the modeller whose work could benefit from the increased scale and quantity of models enabled by LLMs and graph analysis.
How useful are they?
Insofar as results are valid, causal graph modelling is a useful direction for operationalising research in responsible AI.
For developers and governing bodies of responsible AI, identifying which actions will maximise their efforts by taking advantage of virtuous or viscous cycles should support decision making.
In an upcoming article I will document the development of an app that improves the usability of RAI patterns.
Remember— all models are wrong, but some are useful. Or as Picasso put it:
We all know that art is not truth. Art is a lie that makes us realize truth, at least the truth that is given us to understand. The artist must know the manner whereby to convince others of the truthfulness of his lies. — Pablo Picasso, 1923
Further research
Some directions for further research are
- Building a causal graph RAI tool/webapp
- Detecting archetypes in causal graphs (see below images)
- Prompt-tuning for causal graphs
- Causal graph-enabled RAG


Source: Kim D. H. (1994). Systems archetypes. Pegasus Communications.
Bibliography
[[1]]: Lee, S. U., Perera, H., Xia, B., Liu, Y., Lu, Q., Zhu, L., ... & Whittle, J. (2023). QB4AIRA: A Question Bank for AI Risk Assessment. arXiv preprint arXiv:2305.09300.
[[2]]: The team at Data61 CSIRO have published a bank of 293 questions for AI risk assessment: "QB4AIRA" [[1]] which aims to integrate with other AI risk assessment standards and frameworks. Although a Smart Risk Assessment Tool was developed based on the QB4AIRA, the challenge was to find relevant and stage-specific questions according to feedback from one of two testing groups (Ibid., Page 6.)
[[3]]: A similar has been published here— Lu, Q., Zhu, L., Xu, X., Whittle, J., Douglas, D., & Sanderson, C. (2022, May). Software engineering for responsible AI: An empirical study and operationalised patterns. In Proceedings of the 44th International Conference on Software Engineering: Software Engineering in Practice (pp. 241-242).
[[4]]: Jason Wei, et al. "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." arXiv preprint arXiv:2201.11903 (2022).
[[5]]: Li, C., Wang, J., Zhang, Y., Zhu, K., Hou, W., Lian, J., ... & Xie, X. (2023). Large language models understand and can be enhanced by emotional stimuli. arXiv preprint arXiv:2307.11760.
[[6]]: Xu, B., Yang, A., Lin, J., Wang, Q., Zhou, C., Zhang, Y., & Mao, Z. (2023). ExpertPrompting: Instructing Large Language Models to be Distinguished Experts. arXiv preprint arXiv:2305.14688.
[[7]]: Liu, J., Liu, A., Lu, X., Welleck, S., West, P., Bras, R. L., ... & Hajishirzi, H. (2021). Generated knowledge prompting for commonsense reasoning. arXiv preprint arXiv:2110.08387.
[[8]]: Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., ... & Chi, E. (2022). Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625
[[9]]: Tip, T. (2011). Guidelines for drawing causal loop diagrams. Systems Thinker, 22(1), 5-7. https://thesystemsthinker.com/wp-content/uploads/pdfs/220109pk.pdf