Replication: AI research by CSIRO’s Data61

AI and Human Reasoning: Qualitative Research in the Age of Large Language Models
Bano, M., Zowghi, D., & Whittle, J. (2023). The AI Ethics Journal, 3(1).
After reading "AI and Human Reasoning" (Bano et al. 2023) I decided to replicate the study to investigate a critical omission in its experimental design.
The authors compare AI and Human responses when tasked with labelling text according to Schwartz’s theory for Human Values. The aim was to understand how the reasoning abilities of LLMs compare to human comprehension in the context of qualitative research.
Humans and LLMs only agreed about 25% of the time when classifying a dataset of 50 Amazon Alexa product reviews.
PROMPT"Following is an app review from a user of Amazon Alexa. Analyse the review text and classify it against Schwartz’s theory for Human Values, both main and sub values. Provide your reason on why you classified it against that value."↓PRODUCT REVIEW"Alexa helps in many ways and plays my favorite play list and gives me updates on musicians new albums."↓RESPONSEMain Value: AchievementSub-Value: CompetenceReason: The values Alexa's ability to answer difficult questions
Numerical error
A key figure in the article contained an simple numerical error:
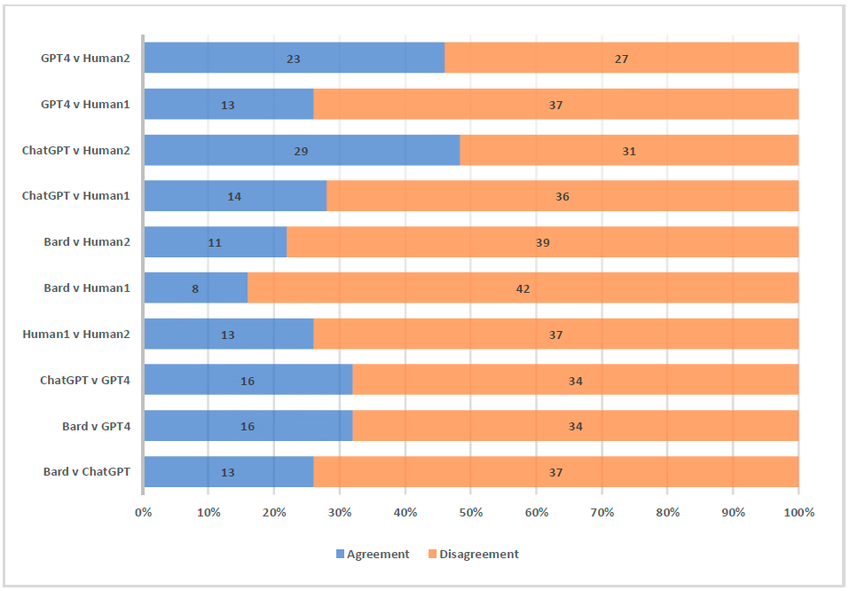
The row ChatGPT + Human2 incorrectly sums to 60. All other rows equal to the sample size of 50.
The original data from the experiment was published and below is my reproduction. Several off-by-one discrepancies have not been verified manually.
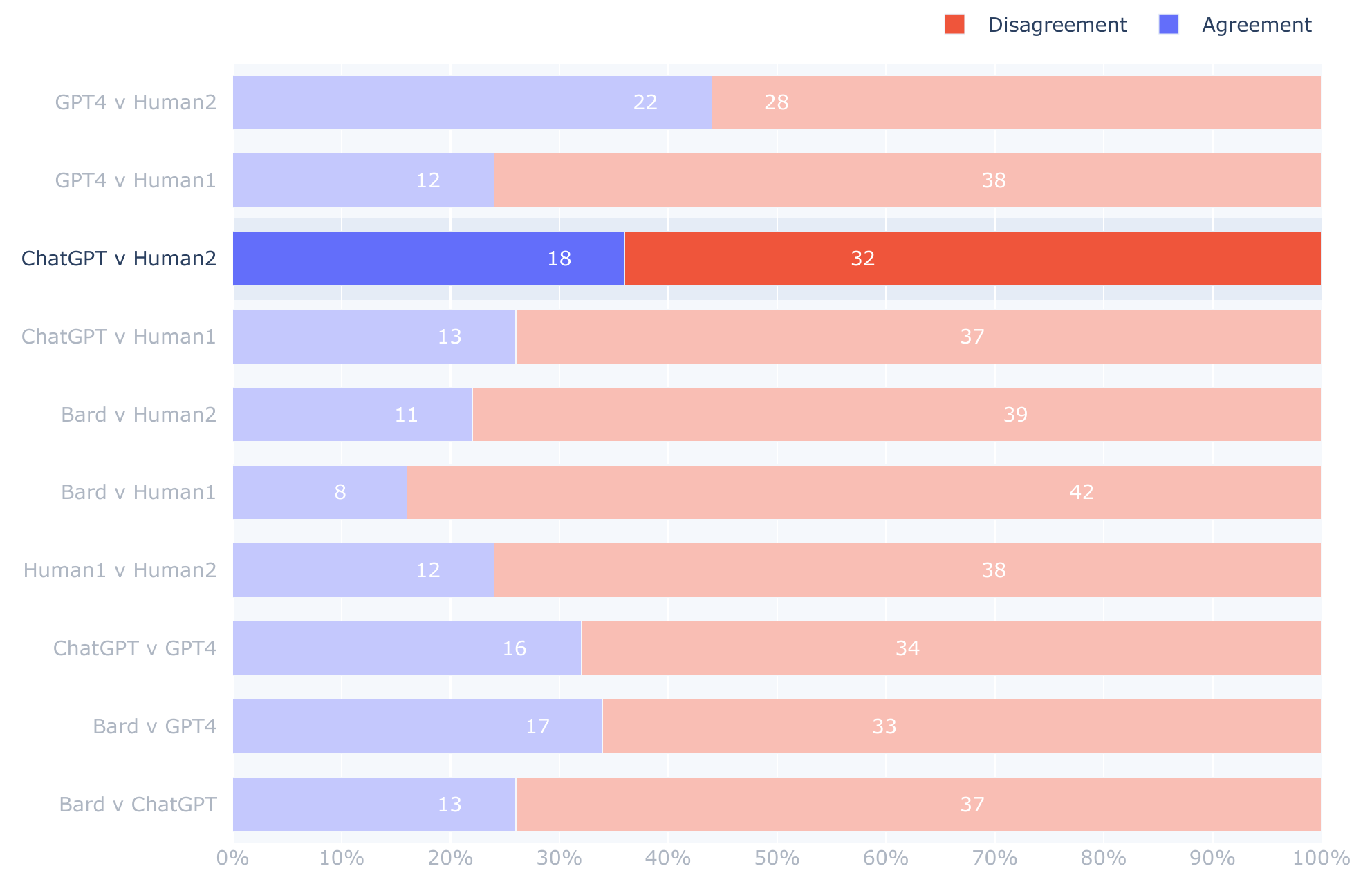
How significant is the miscount?—It appears to have contributed to the interpretation of results according to the authors' remarks
"While AIs show varied levels of agreement with humans, it is noteworthy that ChatGPT has a significant agreement with Human2, suggesting that certain AI models might align more closely with certain human perspectives."
Validity problem
The experiment doesn't control for the effect of different prompts on AI responses. This presents a problem of internal validity for the study because as the authors acknowledge, prompts are a critical factor that can significantly influence the analysis of Large Language Models (LLMs):
"The composition and specificity of prompts can guide the models’ analysis and processing of the task, thus affecting the results. A well-structured, clear, and contextually rich prompt helps the LLMs focus on the essential aspects of the task, reducing the likelihood of errors"
As we will see that approach is necessary but not sufficient for consistently good results.
This effect cannot be ignored because under real world conditions researchers would likely refine their prompts, just as with keyword search using wildcards *, AND/OR operations, spellings, etc.
What effect does varying prompts have?
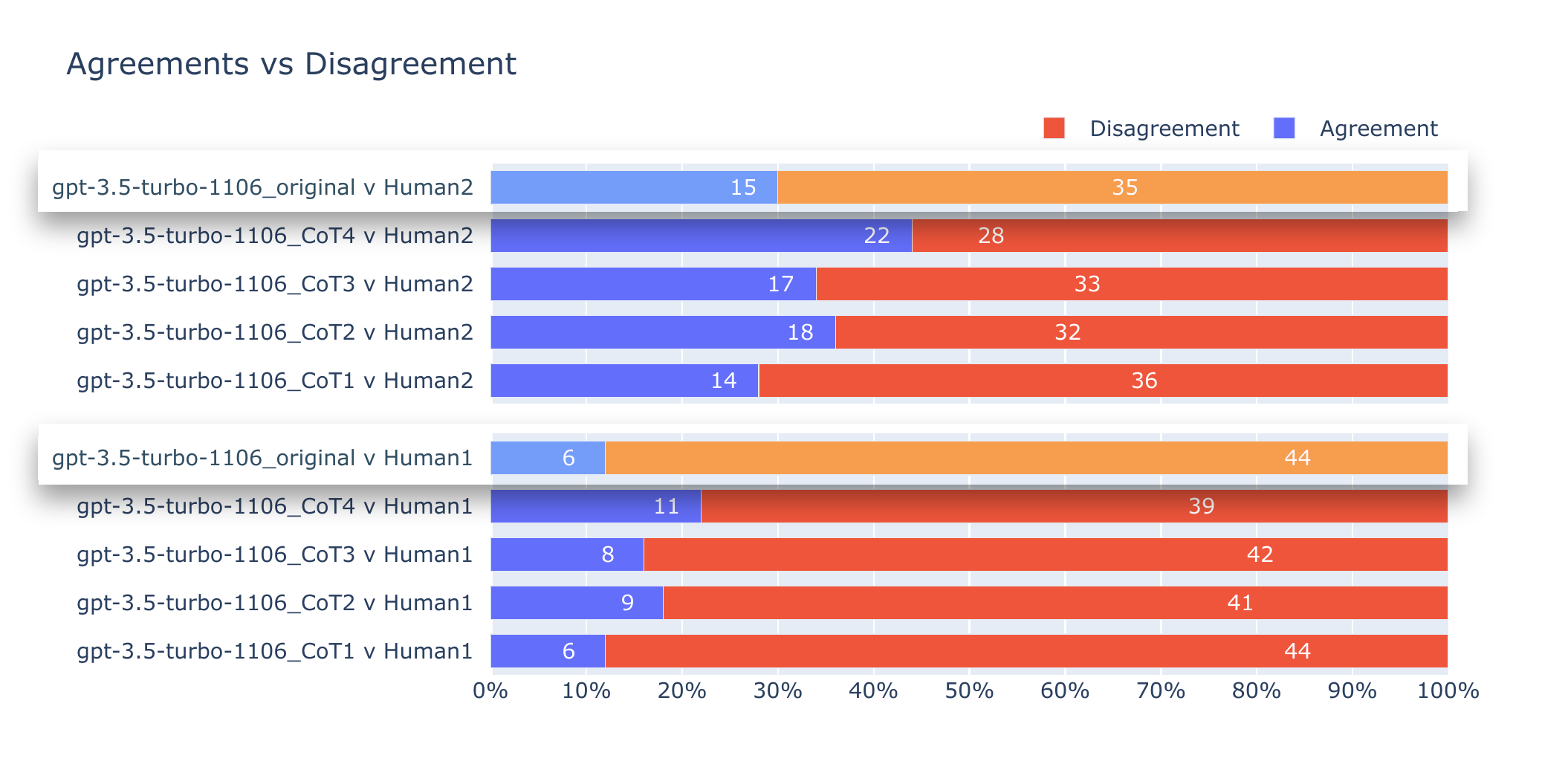
My experiment measured the effect of changing the prompt (without changing model—gpt-3.5-turbo-1106) and comparing results as in the original article.
Prompt changes improved results by up to 1.8× ranked by agreement with Human 1 and Human 2.
The prompt changes (in order of effectiveness):
- Provide examples of answers and Schwartz's Human Values
- Zero-shot Chain-of-Thought prompt [1]
- LLM selects best out of 3 multiple answers
- JSON output.
(See roadmap.sh and learnprompting.org for overview of techniques)
Results
Simply by changing the prompt, AI-generated responses improved by 1.8× and 1.4× when classifying the "Main Value" of Schwartz Human Values to reach agreement with Human 1 and 2 respectively.
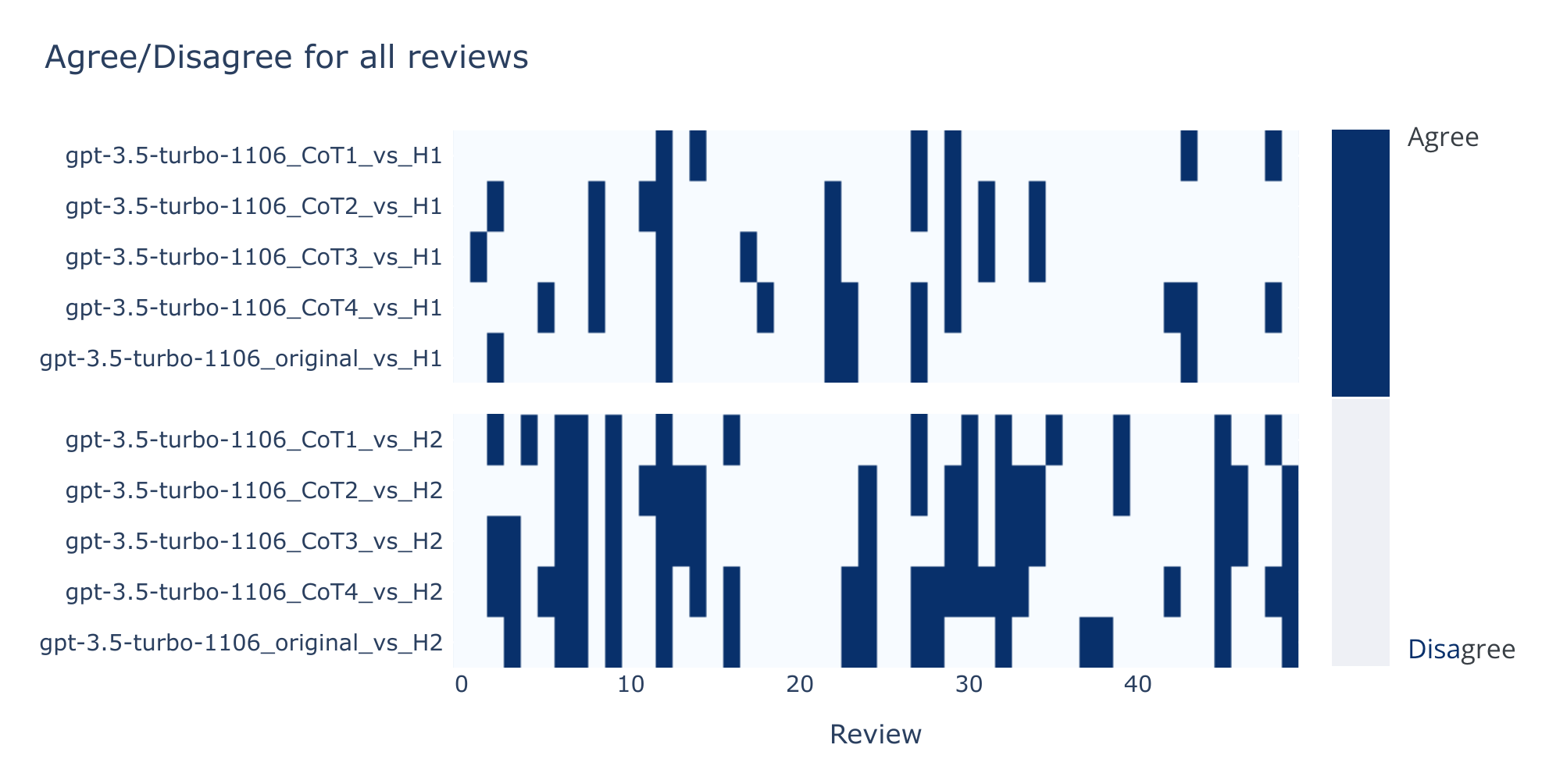
To learn which reviews were resistant to prompt change (vertical white blocks or gaps) the agree/disagree outcome across all prompts was plotted as a heat map:
To indicate the contribution of "reasoning" behind improvements in prompt changes, vector word embeddings were computed from various prompts and Human responses.
In the chart below every dot represents a paragraph explaining the reasoning supporting the classification. Those paragraphs are converted into 768 length dimensions and then reduced to two dimensions shown here:
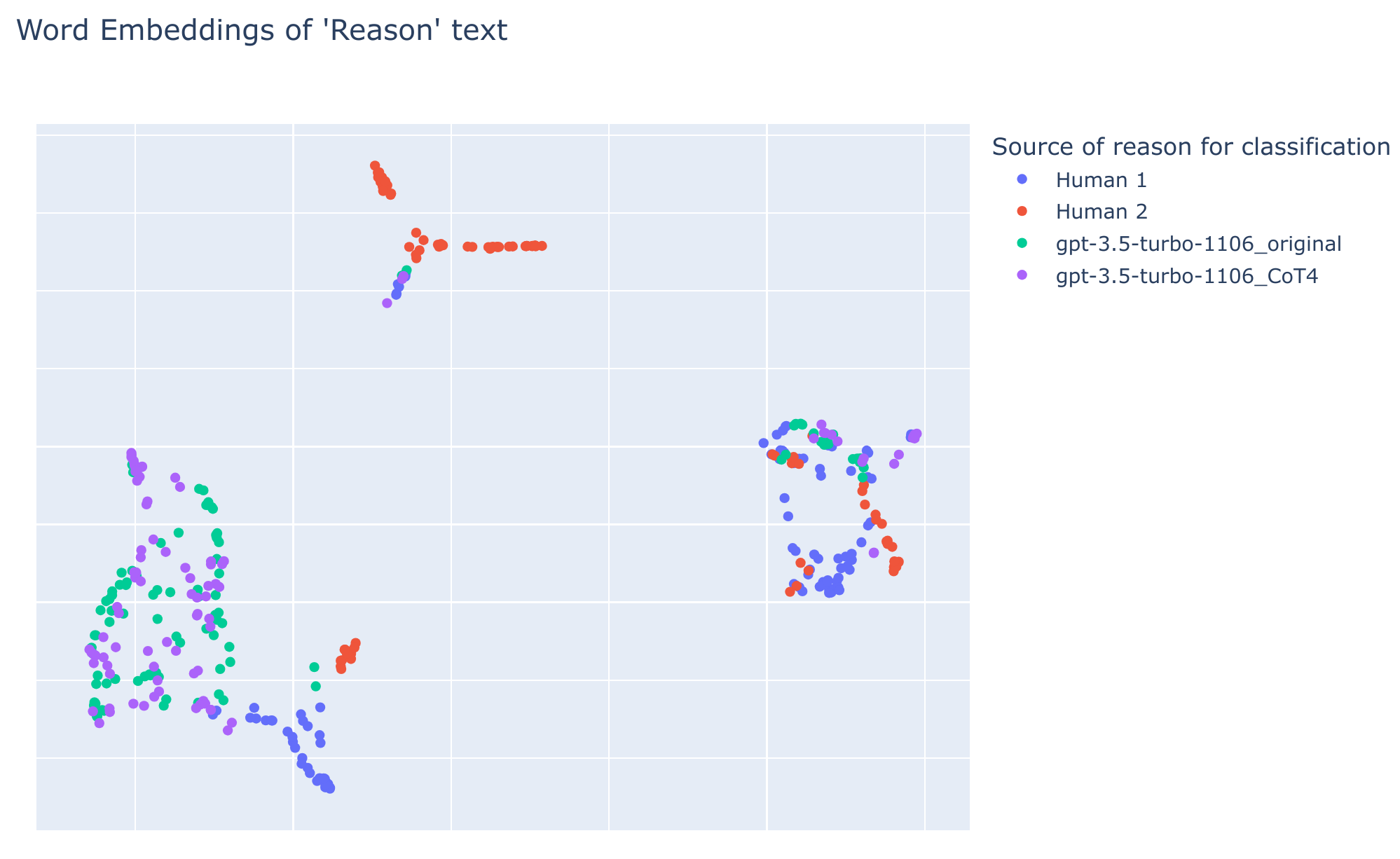
There are three spatially distinct clusters including local variations in the semantics of reasons.
Texts from all sources (human and AI) are co-located in each cluster, but human responses (blue/red) are less overlapping than AI generated ones (purple/green). This is likely caused by different idiosyncratic phrasing by Human 1 and Human 2.
But it also suggests that the reasons given by AI-generated classifications are consistent (at least semantically) despite the vast difference between the prompts used to generate them.
These improvements and semantic relationships indicate that changes to prompts have an impact on the subjective judgement of AI-generated responses.
Researchers performing LLM assisted classification can be expected to optimise their prompts. Any comparison between AI-generated and human classification should take this into account.
In the next article, I will delve into more advanced prompt engineering that will enable modifiable outputs to move value bias between Human 1 or 2.
APPENDIX
Chain of Thought Prompts:
CoT1
Classify the text according to only one value from Schwartz's theory for Human Values. Provide a Reason to help me understand your thought process. For example, {"app_review": "Adding photos would be nice if you could rotate photos", "reason": "User expects creativity in editing photos by Alexa", "main_value": "Creativity"}. App Review: {text}. Now let's think this through step by step, write your answer in valid JSON with keys app_review, main_value, reason:
CoT2
Classify the text according to only one value from Schwartz's theory for Human Values. Use the following as a guide: 'Benevolence' reflects the priority of caring for the welfare of related people and in-group members. 'Universalism' refers to the understanding, appreciation, tolerance, and protection for the welfare of all people and for nature. 'Tradition' expresses the respect, commitment, and acceptance of the customs and ideas that traditional culture or religion provides. 'Conformity' expresses restraints of actions, inclinations, and impulses to upset others and compliance with social expectations or norms. 'Security' represents the pursuit of personal safety and societal stability. 'Achievement' refers to pursuing personal success through demonstrating performance and competence according to social standards. 'Hedonism' represents the priority of pleasure, satisfaction, and sensuous gratification for oneself. 'Power' reflects the importance of social status and prestige, dominance over others, and control of material resources. 'Stimulation' can be defined as the pursuit of excitement, novelty, and challenge in life. 'Self-direction' reflects the importance of autonomy of thought and action (i.e., choosing, creating, and exploring). Provide a Reason to help me understand your thought process. For example, {"app_review": "Adding photos would be nice if you could rotate photos", "reason": "User expects creativity in editing photos by Alexa", "main_value": "Creativity"}. App Review: {text}. Now let's think this through step by step, write your answer in valid JSON with keys app_review, main_value, reason:
CoT3
As an expert sociologist, assign one main value from Schwartz's theory for Human Values to the following customer review (app_review). Schwartz's theory for Human Values:
'Benevolence': reflects the priority of caring for the welfare of related people and in-group members.
'Universalism': refers to the understanding, appreciation, tolerance and protection for the welfare of all people and for nature.
'Tradition': expresses the respect, commitment, and acceptance of the customs and ideas that traditional culture or religion provides.
'Conformity': expresses restraints of actions, inclinations, and impulses to upset others and compliance with social expectations or norms.
'Security': represents the pursuit of personal safety and societal stability.
'Achievement': refers to pursuing personal success through demonstrating performance and competence according to social standards.
'Hedonism': represents the priority of pleasure, satisfaction, and sensuous gratification for oneself.
'Power': reflects the importance of social status and prestige, dominance over others, and control of material resources.
'Stimulation': can be defined as pursuit of excitement, novelty, and challenge in life.
'Self-direction': reflects the importance of autonomy of thought and action (i.e., choosing, creating, and exploring).
Now let's think this through step by step, write your answer in valid JSON with keys app_review, main_value, reason.
app_review: {text}
CoT4
Insert the three most relevant Schwartz Human Values in a json list [] in sub_value key according to Schwartz's theory for Human Values you think app_review is expressing. Also provide 1 main_value. Use the following as a guide: 'Benevolence' reflects the priority of caring for the welfare of related people and in-group members. 'Universalism' refers to the understanding, appreciation, tolerance and protection for the welfare of all people and for nature. 'Tradition' expresses the respect, commitment, and acceptance of the customs and ideas that traditional culture or religion provides. 'Conformity' expresses restraints of actions, inclinations, and impulses to upset others and compliance with social expectations or norms. 'Security' represents the pursuit of personal safety and societal stability. 'Achievement' refers to pursuing personal success through demonstrating performance and competence according to social standards. 'Hedonism' represents the priority of pleasure, satisfaction, and sensuous gratification for oneself. 'Power' reflects the importance of social status and prestige, dominance over others, and control of material resources. 'Stimulation' can be defined as pursuit of excitement, novelty, and challenge in life. 'Self-direction' reflects the importance of autonomy of thought and action (i.e., choosing, creating, and exploring). sub_values examples: [Wisdom, Variety, Understanding, appreciation, Understanding, Trust, Tolerance, Success, Stimulation, Social order, Social justice, Sensuous gratification, Self-discipline, Security, Safety of Self, Safety, Rules, Restraint, Responsiveness, Respect for tradition, Respect, Resource Efficiency, Productivity, Privacy, Preventing harm, Politeness, Pleasure, Playfulness, Personal success, Personal safety, Peace, Order, Obedience, Novelty, Norms, Loyalty, Knowledge Justice, Interpersonal harmony, Intelligence, Humility, Honesty, Helping others, Helpful, Frustration, Freedom, Excitement, Equality, Enjoyment of life, Enjoyment, Enjoying life, Enjoying Life, Diversity, Dependability, Curiosity, Creativity, Control over one's life, Control, Concern for the welfare of others, Competence, Commitment, Comfort, Choosing own goals, Choice, Challenge, Caring for others, Caring, Care, Capabilities, Benevolence, Authority, Acceptance of others]. Provide a Reason to help me understand your thought process. For example, {"app_review": "I'd enjoy and find this app very useful if it did WHAT it was supposed to WHEN it was supposed to", "reason": "Alexa app is not functioning as expected, impacting the user's productivity.", "main_value": "Achievement","sub_value": ['Capability', 'Competence'] }. App Review: {text}. Now let's think this through step by step, first observe the behavior, expectation and outcomes expressed by the user, then figure out the list of 3 main values write your answer in valid JSON with keys app_review, main_value, sub-values, reason: